For Once, a Cold-Start Recommender Shows Its Work
An EPFL arXiv paper introduces an auditable cold-start recommendation framework called GRECS, beating the popularity baseline by up to 198 percent across five standard datasets. For apparel retailers under governance pressure, it is the first cold-start system they can defend in writing.
Neritus Vale
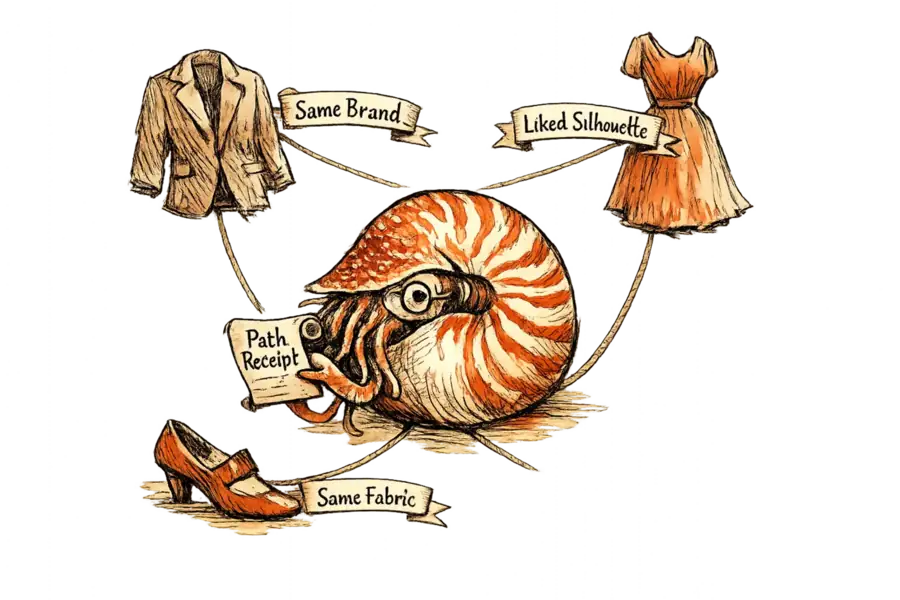
An EPFL paper on arXiv introduces a cold-start adaptation of graph-reasoning recommendation: every suggestion is delivered as an explicit, auditable walk through a knowledge graph. On the Amazon Clothing benchmark, UPGPR0 beats the popularity baseline for users with no interaction history by 119 percent in nDCG. The paper is called GRECS. The finding that matters is not in the benchmark column. Previous cold-start systems either hid inside embeddings no one could inspect, or bolted an explanation onto a language model after the fact. GRECS does neither: its recommendations are paths, and every path is a receipt.
Apparel has the worst version of the cold-start problem in retail. Drop-based merchandising, seasonal SKU churn, and an unusually high rate of first-time shoppers mean that, on any given day, a meaningful share of a site’s catalogue and a meaningful share of its visitors are unknown to the recommender. The standard answer, matrix factorisation with auxiliary side features, has spent a decade pretending this is a sparsity problem. It is also a legibility problem. Retailers have no way to tell a confused shopper, a returning customer, or a regulator why the system offered what it did.
GRECS’s numbers are a rebuke to the specialised cold-start literature of the last decade. Built by Jibril Frej, Marta Knežević, and Tanja Käser at EPFL, the paper tests across five standard datasets: Amazon Beauty, CDs and Vinyl, Cellphones, Clothing, and the COCO MOOC corpus. Their best algorithm, UPGPR, strips out the hand-crafted path patterns earlier graph-reasoning methods relied on, and rewards the agent only when the walk lands on an item a user actually touched. On strict cold-start users the uplift is uncomfortable reading for the field: 198 percent over the popularity baseline on Beauty, 116 percent on Cellphones, 119 percent on Clothing. Two specialised cold-start baselines, MKR and SpectralCF, actually underperform a plain popularity recommender. The field has been claiming progress while shipping worse systems.
An LLM-generated explanation for a cold-start recommendation is a second story told about the first one, by the same narrator. Post-hoc justification systems can generate readable natural-language rationales for a recommendation — the text is fluent and the citations plausible. But the explanation and the ranking emerge from separate processes: the explanation encodes nothing about the path the model actually took to produce the result. A GRECS path, by contrast, is a walk the reader can take themselves, and that is the distinction cold-start recommendation has spent a decade avoiding.
GRECS delivers something the leaderboard cannot measure: an auditable recommendation. It produces explicit paths through a knowledge graph — “user liked Brand X; Brand X makes Item Y; Item Y is recommended” — that a product manager can read and a regulator can inspect. Embedding methods force a binary choice: trust the loss curve, or throw the suggestion out. With paths, the operator can argue with the specific relation that produced the ranking. That is the difference between a black-box score and a testable claim. Apparel boards that have spent eighteen months writing AI governance policies without a single auditable recommender finally have something to point at.
The strongest objection is that GRECS only works if the knowledge graph beneath it is rich and clean. Sparse or inconsistent catalogue tags, with style codes mislabelled, attributes missing, and brand hierarchies flattened, degenerate the graph and make the paths trivial: user bought jeans, recommend jeans. The authors concede this indirectly: their null-embedding variant, which assumes no useful metadata, achieves 21 percent cold-item coverage on Beauty against 33 percent for the translation-embedding version. The objection holds, and its real content is an invoice for catalogue work apparel retailers have spent a decade postponing. The precondition for auditable cold-start recommendation is a catalogue ontology most of them have not yet built, and it is not going to build itself.
That caveat is not small.
If apparel retailers accept the premise that cold-start is a legibility problem and that opaque embeddings cannot remain a production default, the work moves upstream into taxonomy, attribution, and style-ontology design — the quietest and least-watched parts of a catalogue team. Those who invest there will, for the first time, be able to defend a recommendation in writing. The retailers that do not will still be shipping suggestions they cannot explain to a shopper, a buyer, or a regulator, and still calling the result “personalisation.” If governance pressure continues at its current rate, that word is going to have to mean something a retailer can read out loud.